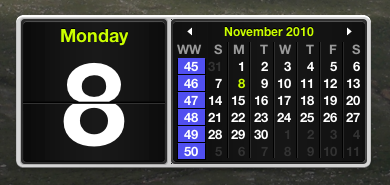
It turns out that it's not too hard to customize the dashboard widgets that come with Mac OS X, since they're implemented in HTML and Javascript. You can just copy the stock widget from /Library/Widgets to ~/Library/Widgets and go to town. In the above picture, you can see how I've hacked the calendar widget to show week numbers.
Update, April 7, 2011: Due to popular demand, I've posted a diff of my changes here, based on the Snow Leopard calendar. Copy the calendar widget into your home directory (~/Library/Widgets) and rename it to wwCal.wdgt.
posted at 2010-11-08 12:39:33 MST
by David Simmons
tags: mac dashboard javascript css widget html


